I’ve solved most of the workflow problems with the RubyNation 2011 video content from the main room,...
Technology
Rails layouts are a nice way to organize boiler-plate HTML content in a DRY (“Don’t Repeat Yourself”...

Last Wednesday, my Verizon FIOS Internet connection went down for the entire day. What was amazing to...
I’m currently reading Russ Olsen’s new technical book, “Eloquent Ruby.” It’s an excellent book. I particularly like...
This is the first of a short series of articles introducing git to new users. Git is a source...
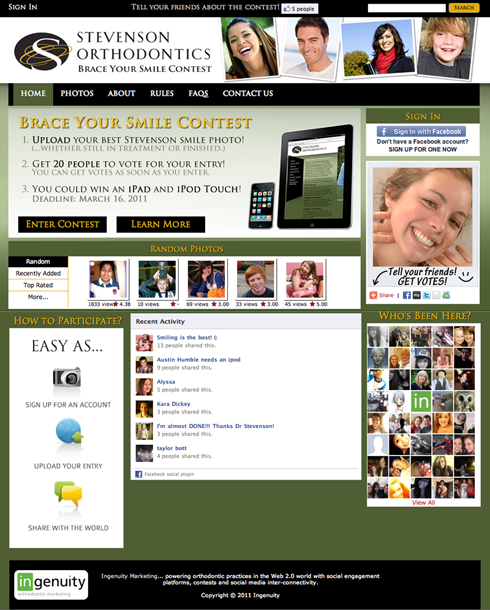
This is another online photo contest that we’ve just fielded using the Votridea contest platform, created by my...
This is a an excellent WordPress presentation from Brad Williams, the author of “Professional WordPress Design and...

This article defines a real-life scenario for a payment processing flow that allows an organization to process...
I recently participated in the design and implementation of an online video contest for a major government...

The Washington Business Journal interviews Main Street Bank exec Jeff Dick about his AirBanking initiative. AirBanking mixes...



